As part of my Intro to Industrial Engineering course, I completed a data analysis project focused on tornado occurrences in the United States between 1950 and 2021. Using Excel, I created four assertion-evidence slides to explore different questions related to tornado frequency, severity, location, and impact. Each graph was designed to support a clear conclusion based on the data, following principles of effective data visualization and storytelling.
The dataset contained historical records of all reported tornadoes in the U.S. during that time period, and included both numerical and categorical variables. The represented columns were as follows: year, month, day, state, EF level (magnitude), number of injuries, number of deaths, start and end longitude, start and end latitude, tornado path length (in miles), and width (in yards). This wide range of variables allowed for a detailed exploration of various tornado-related phenomena, both temporal and geographic.
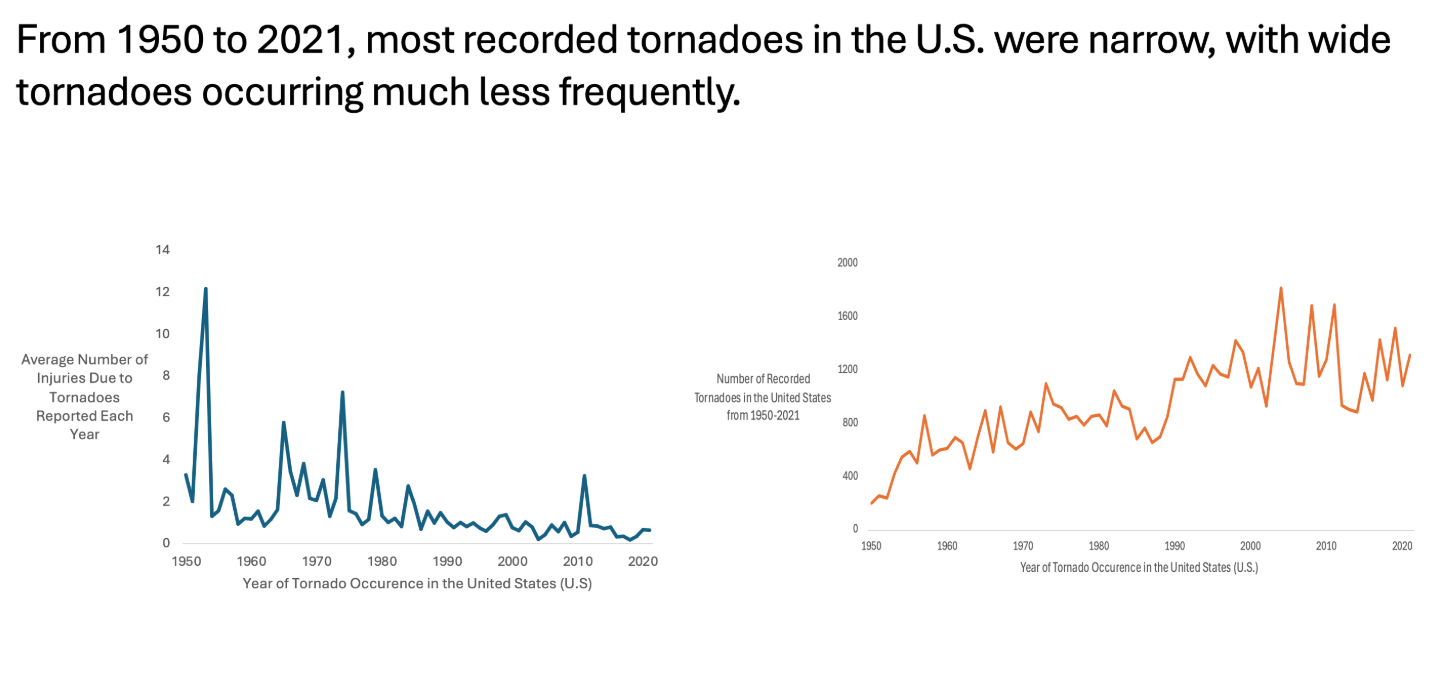
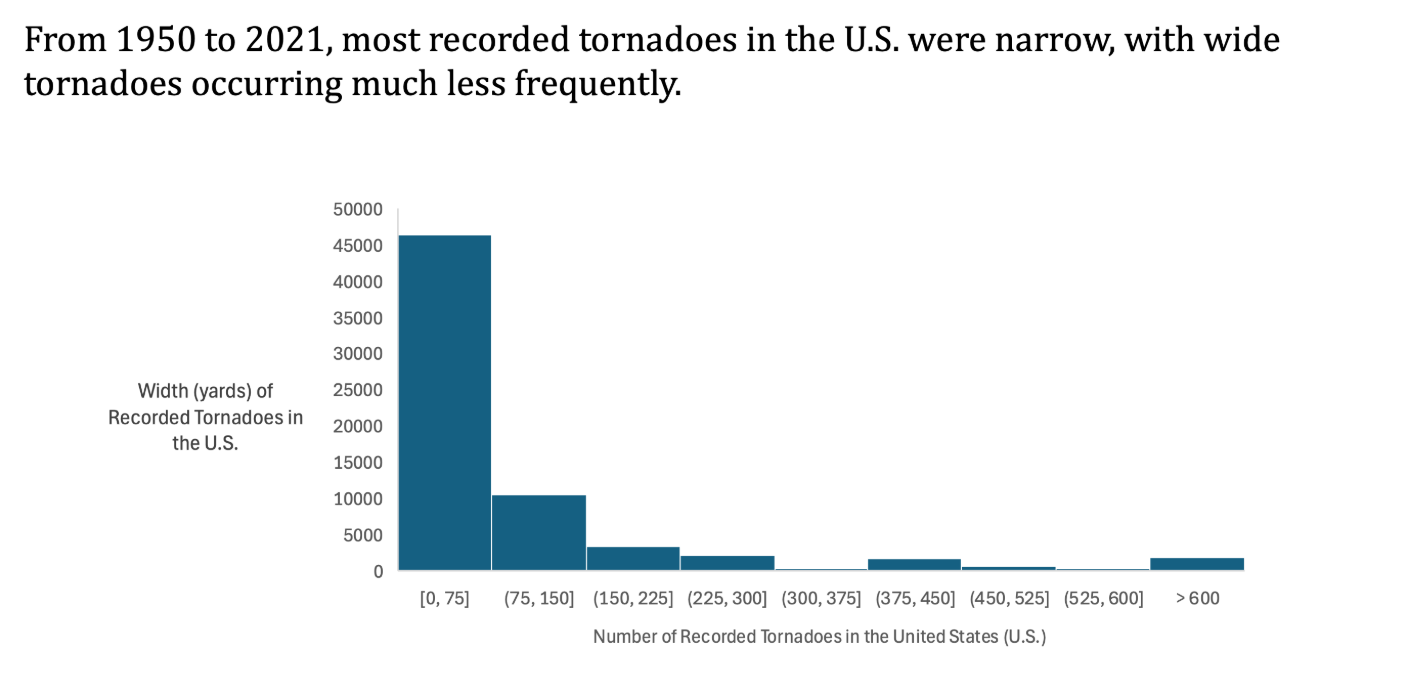
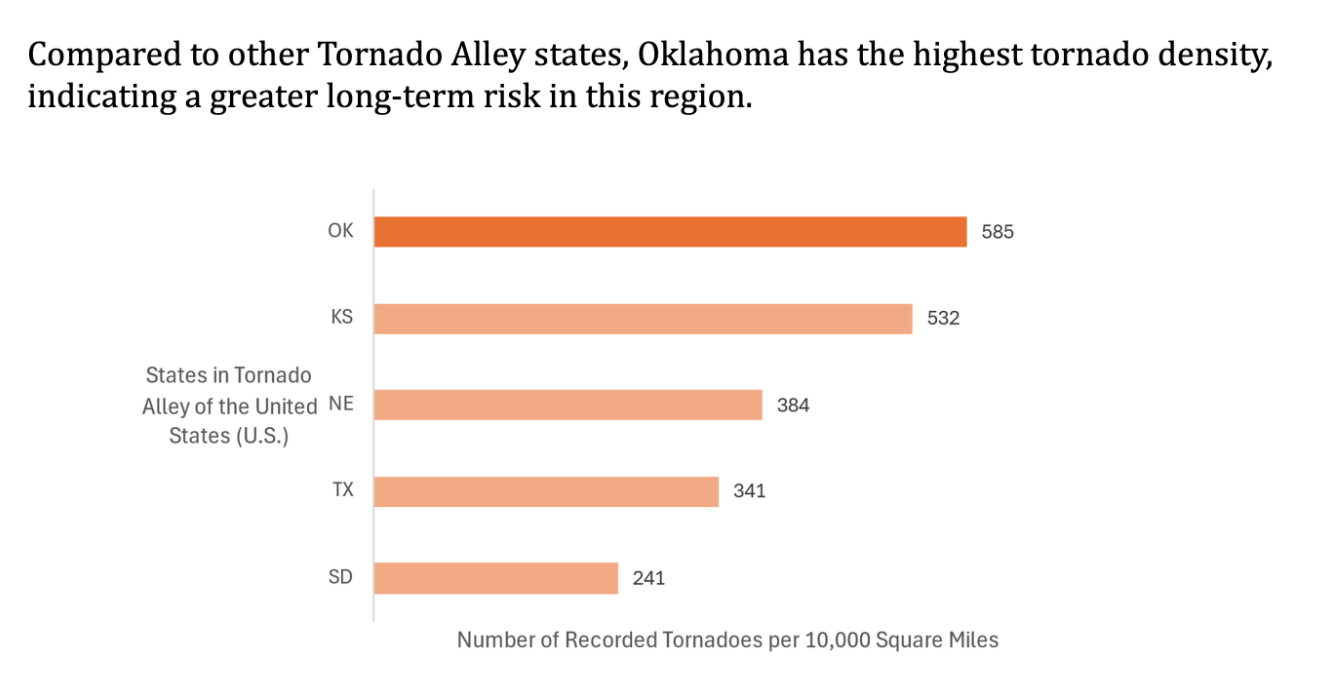
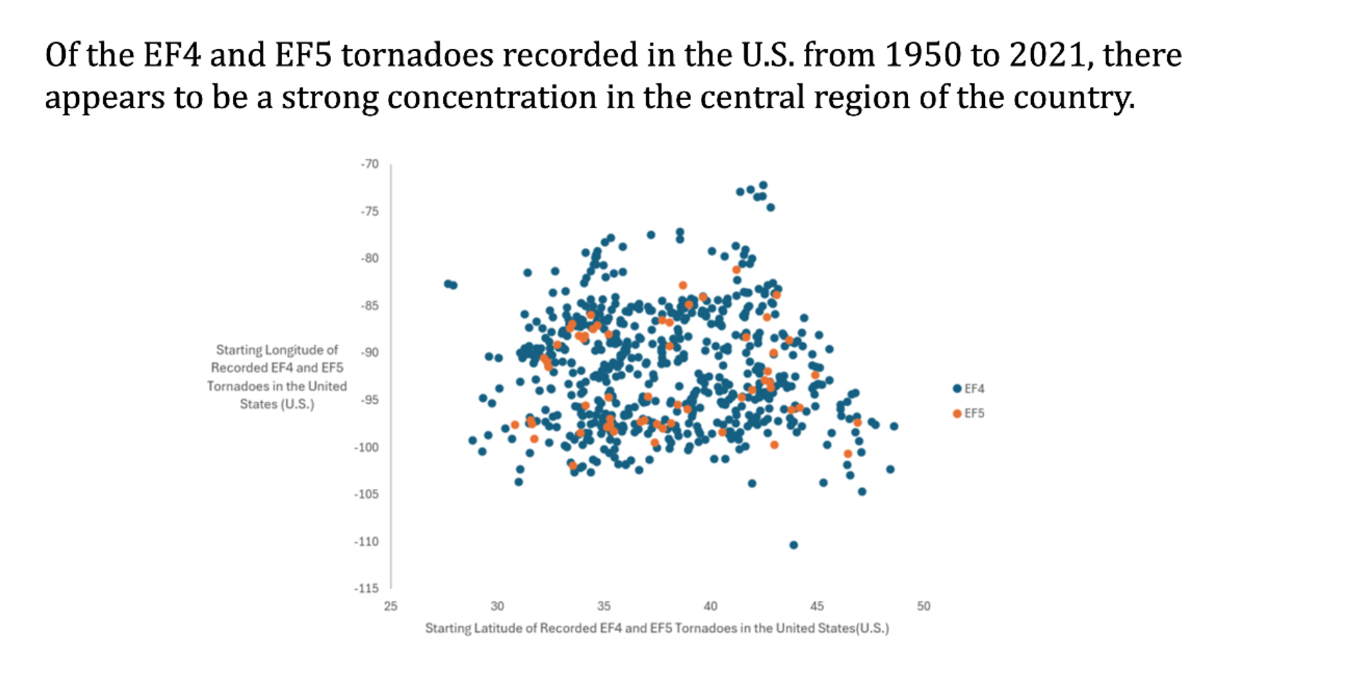
This project gave me the opportunity to apply Excel-based data analysis tools such as pivot tables, custom binning, and multi-variable filtering. More importantly, it taught me how to craft compelling visualizations that connect data to insights, and how to interpret large datasets to answer complex real-world questions. Each slide was carefully designed to balance clarity, simplicity, and impact—core principles in both engineering analysis and effective communication.